VIZ_01: WHO IS TALKING
data source: corpus dataset
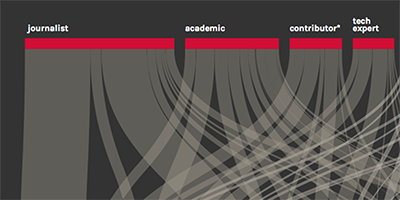
data selected: author profession, media type
Creating (starting from corpus dataset) a csv file containing only data relating to author profession and media type.
VIZ_02: SPECIFICATION OF SINGLE SPEAKER/PARTICIPANT
data source: corpus dataset + twitter and wikipedia
data selected: author name, author profession, website name, polarization
Creating (starting from corpus dataset) a csv file containing author name, author profession and website name who have written more than one article of the corpus, everyone associated with the number of repetitions. To each person we have also associated the number of follower and tweet.
The five most important authors are presented with a short description comes from personal profiles and wikipedia.
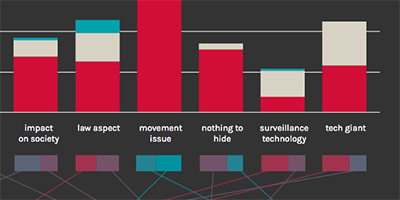
VIZ_03: POLARIZATION WITHIN THE MOST RELEVANT TOPIC AND MEDIA
data source: corpus dataset
data selected: topic, polarization, media type
Creating (starting from corpus dataset) a csv file containing topic, number of pages for topic splitted by polarization (in favor of surveillance, against surveillance, neutral) and the total of the speakers who talk about that particular topic.
In addition, for each topic are presented the two media that speak more, information obtained by a simple counting operation.
VIZ_04: SPEAKERS AND RELEVANT WORDS
data source: corpus dataset, Sven
data selected: link, author’s profession, polarization (corpus) + word, tf valor (sven results)
Creating a specific dataset to categorize Sven results:
- creation of file containing links, categorised by media and polarization;
(es: academic_against.doc, academic_neutral.doc, academic_infavour.doc)
- extraction of txt through Zup
- txt organization in groups/folders relative to media and their polarization
(es: ..>academic>against, ..>academic>neutral, ..>academic>in favour)
- Sven: creation of a corpus for each txt group/folder, analysed separately
- selection of Sven results with the highest tf value and incorporation with the previous dataset
- creation of a csv file with the repetition count of the selected word.
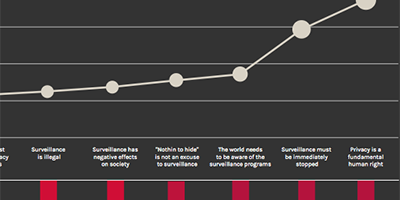
VIZ_05: WHERE THE DEBATE IS - TREND AND NUANCES
data source: corpus dataset
data selected: statement, polarization (against), author’s profession (against)
Creating (starting from corpus dataset) a csv file containing statement used for siding against surveillance and the number of pages for topic against surveillance. In addition, for each topic is presented the breakdown of the speakers who talk about it: for this purpose has been created another dataset composed by the number of speakers (author’s profession) for each topic as a percentage.