Introduction
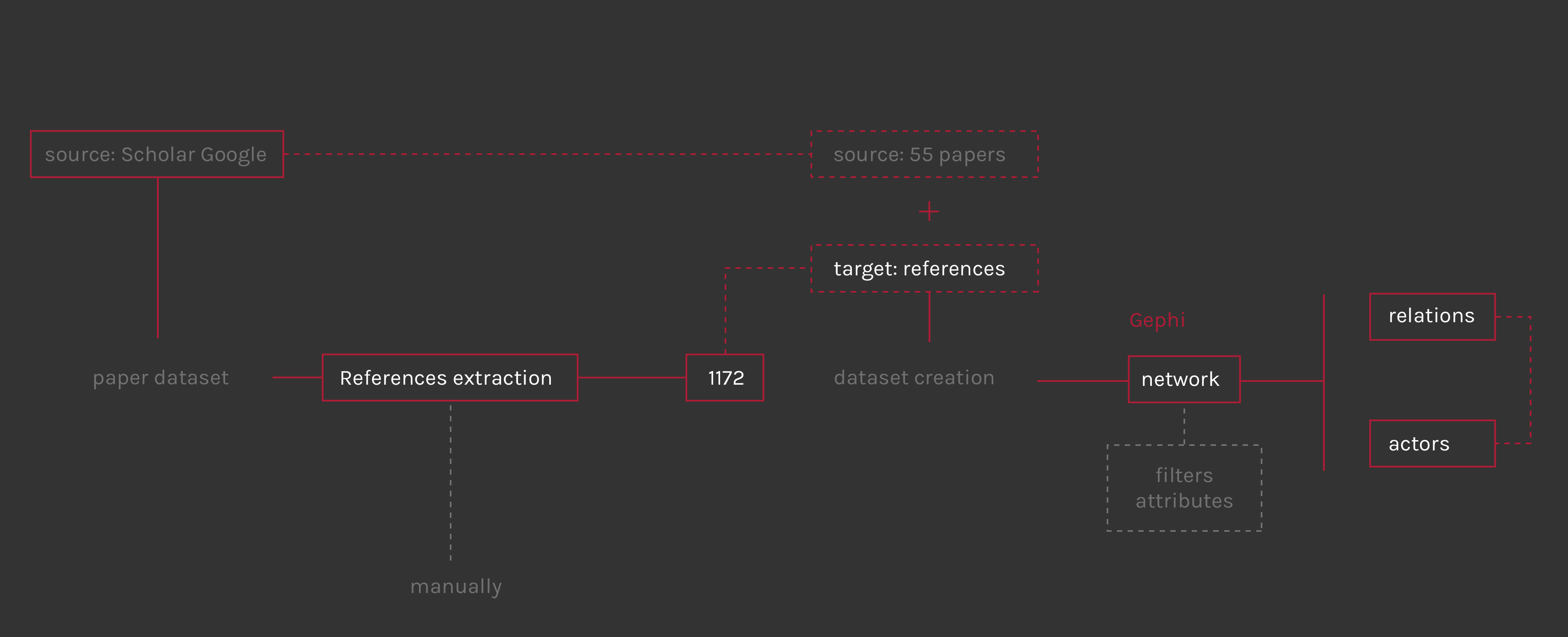
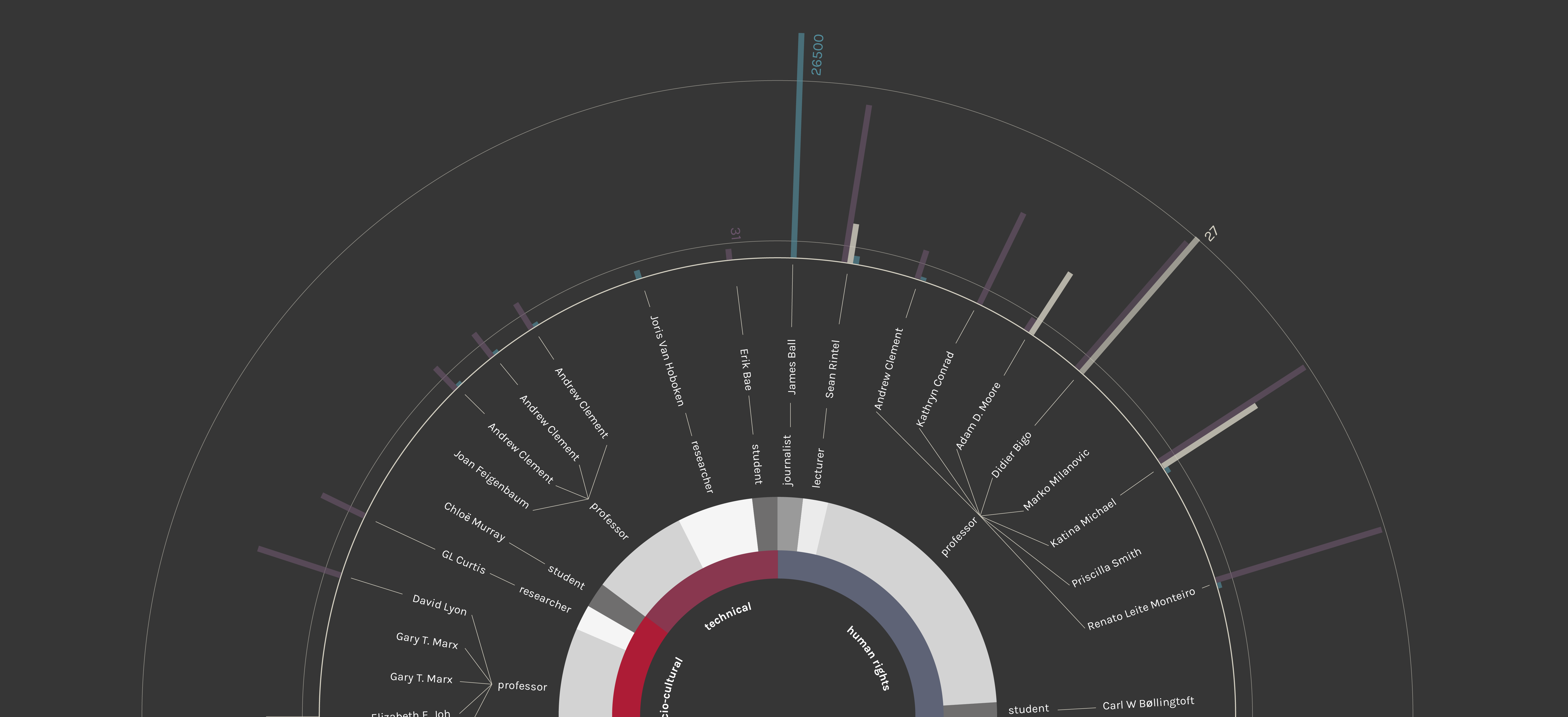
The third chapter focuses on how the debate in the academic world is developing. As in the second resarch step, those who debate on electronic mass surveillance on the web are journalists and academics. To have a more technical and deeper idea about the debate the academic world has been studied. It is interesting to look at the main topic from a technical and expert point of view. The speakers, as shown in the next chapters, have different skills and comes from different field of studies. This chapter mainly concerns in three parts, starting from a general overview of the speakers to a deep analysis of the relations among them and the other actors. The main source is Google Scholar, from which the papers and articles were taken into account. Five queries were used, quite similar to the ones used for the second step (chapter 02) but more specific, to collect results as pertinet to the issue as possible.