Introduction
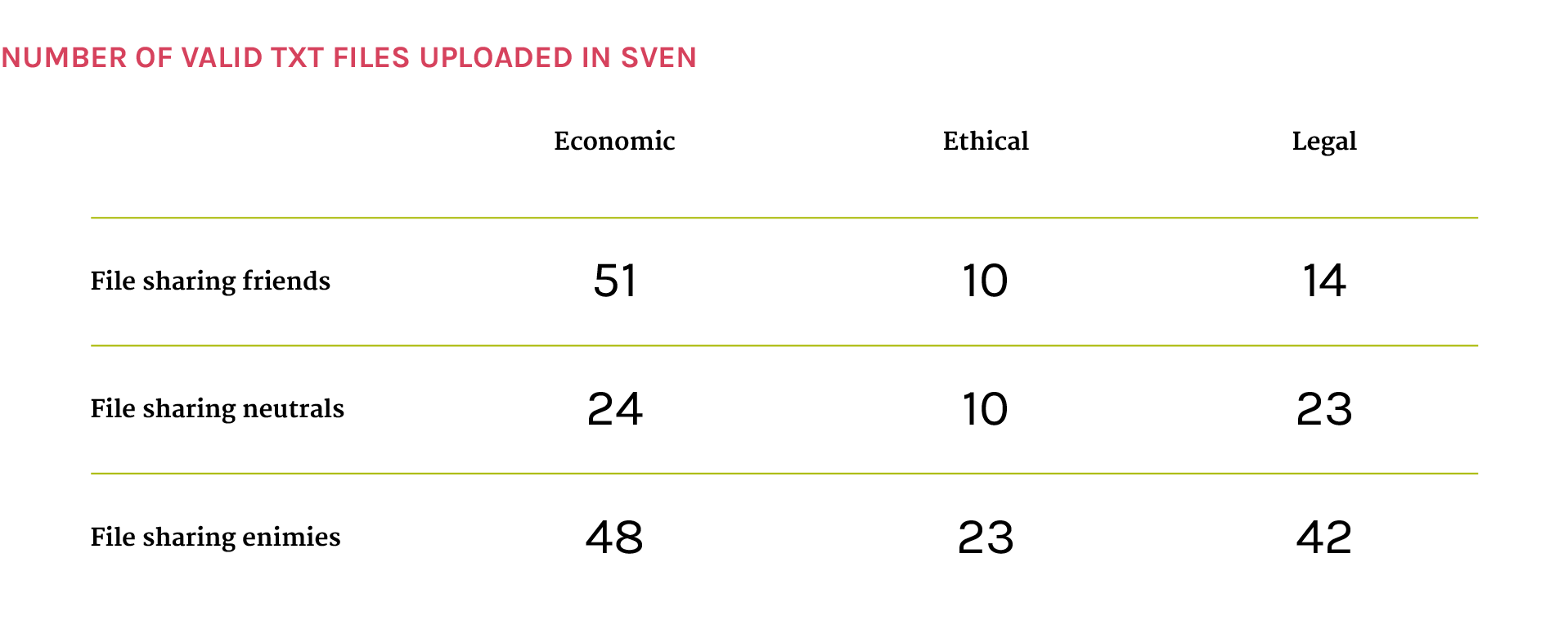
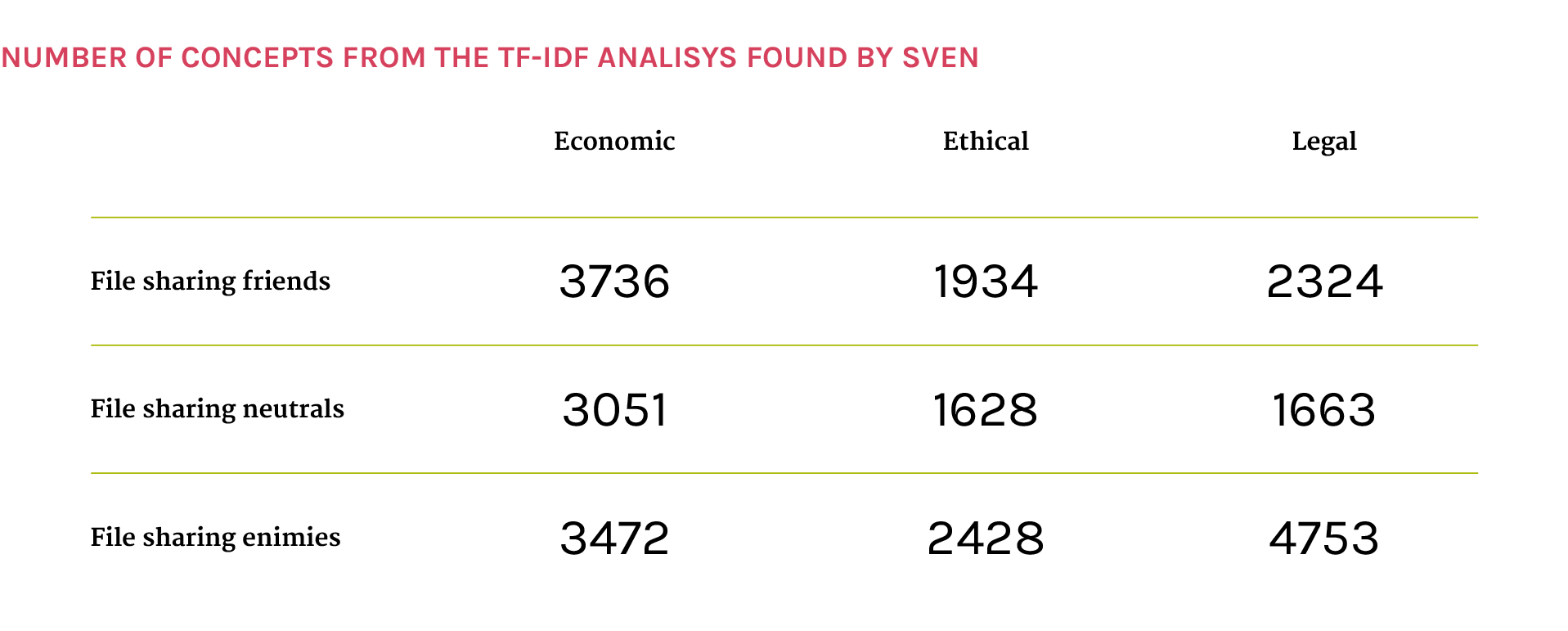
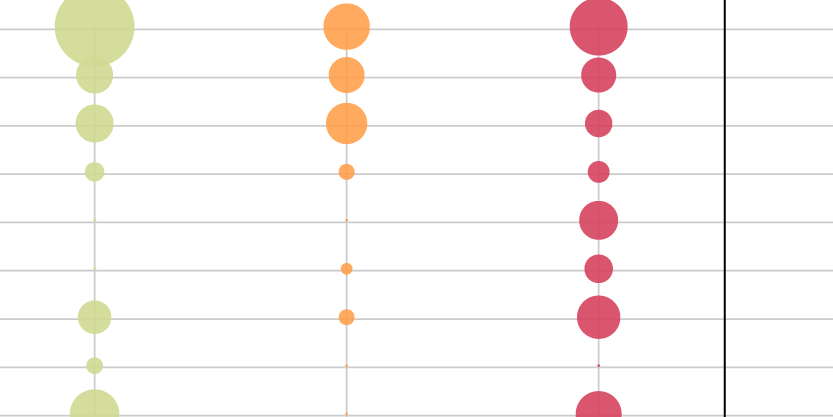
The graph shows the results of TD-IDF analysis made on the texts taken from the first 200 web pages taken from Google. It shows which are the more pertinent concepts divided for area of interest (economic, ethical and legal) and for taken position about file sharing (friends, neutral and enimies).