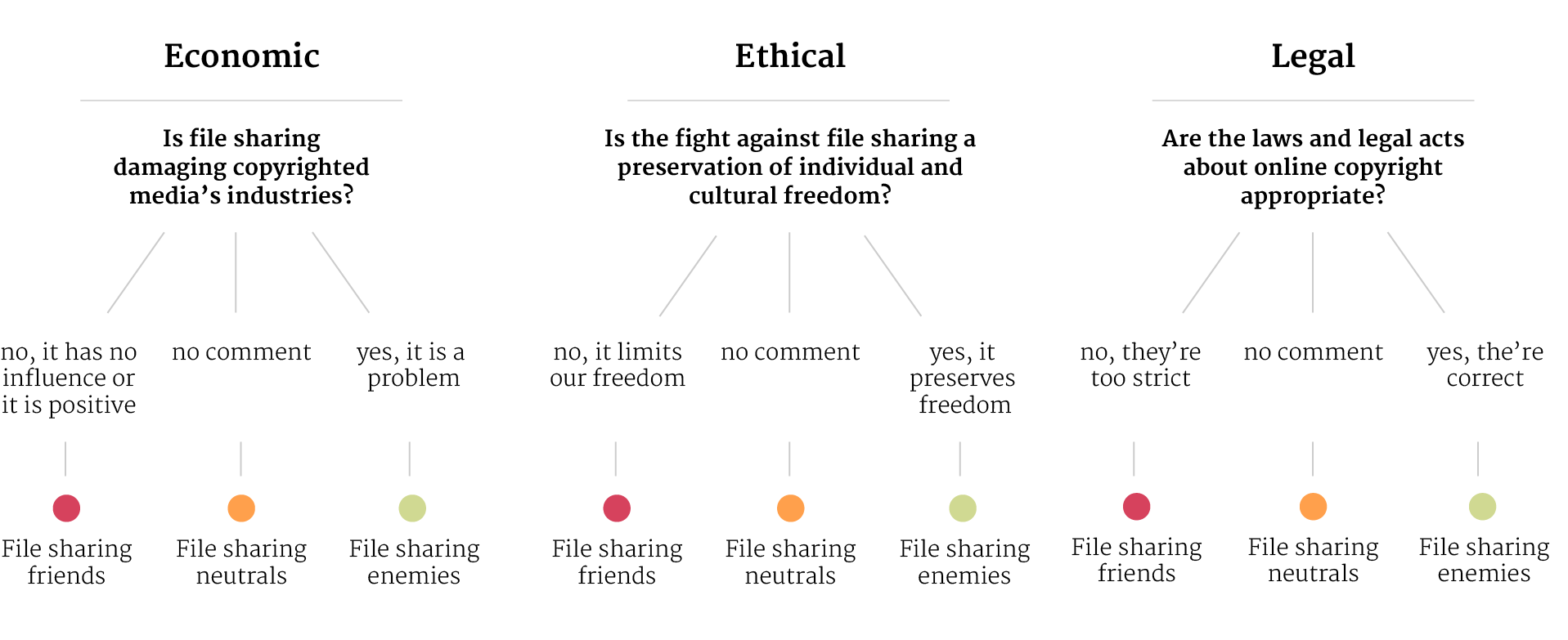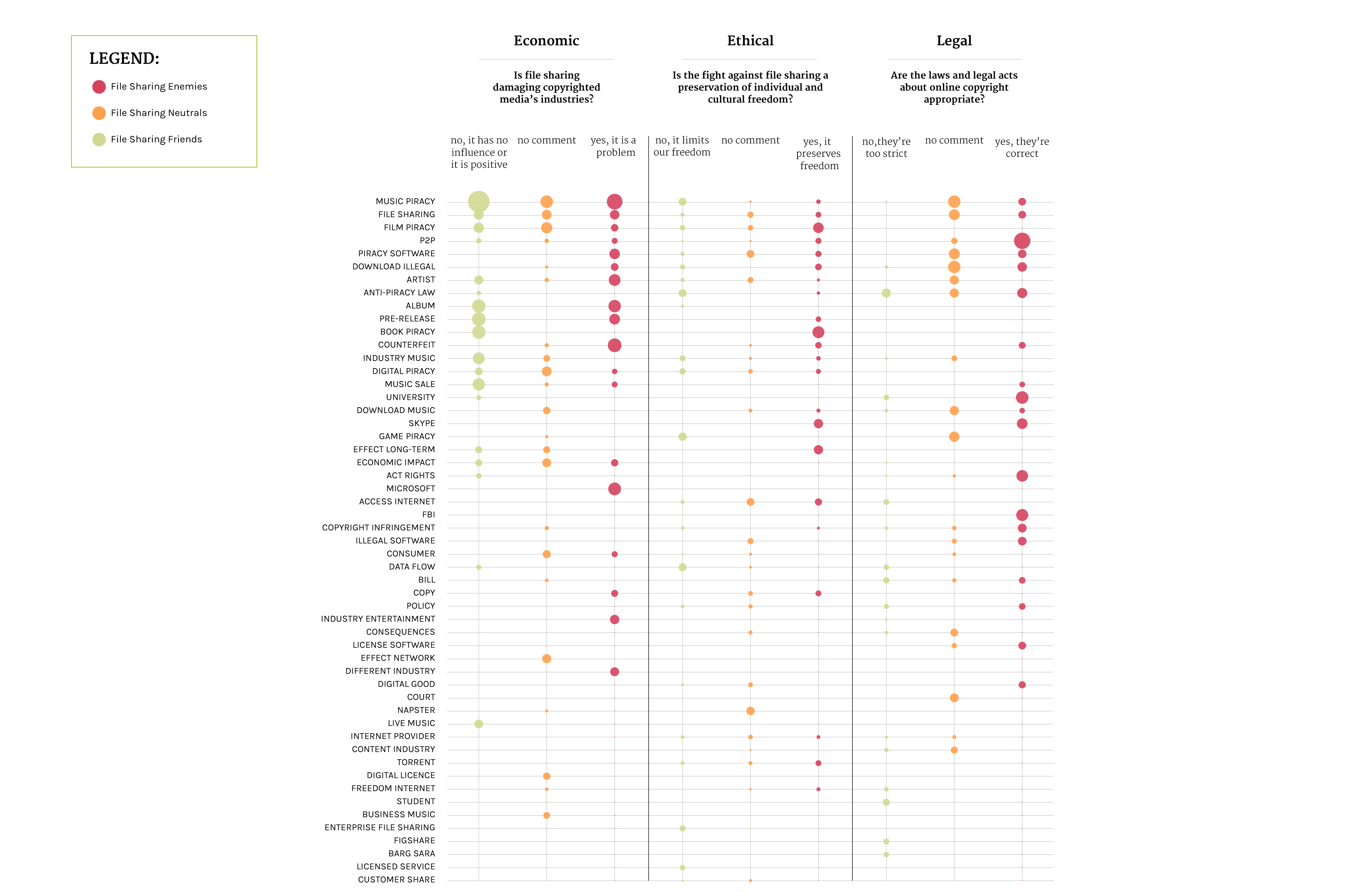
Introduction
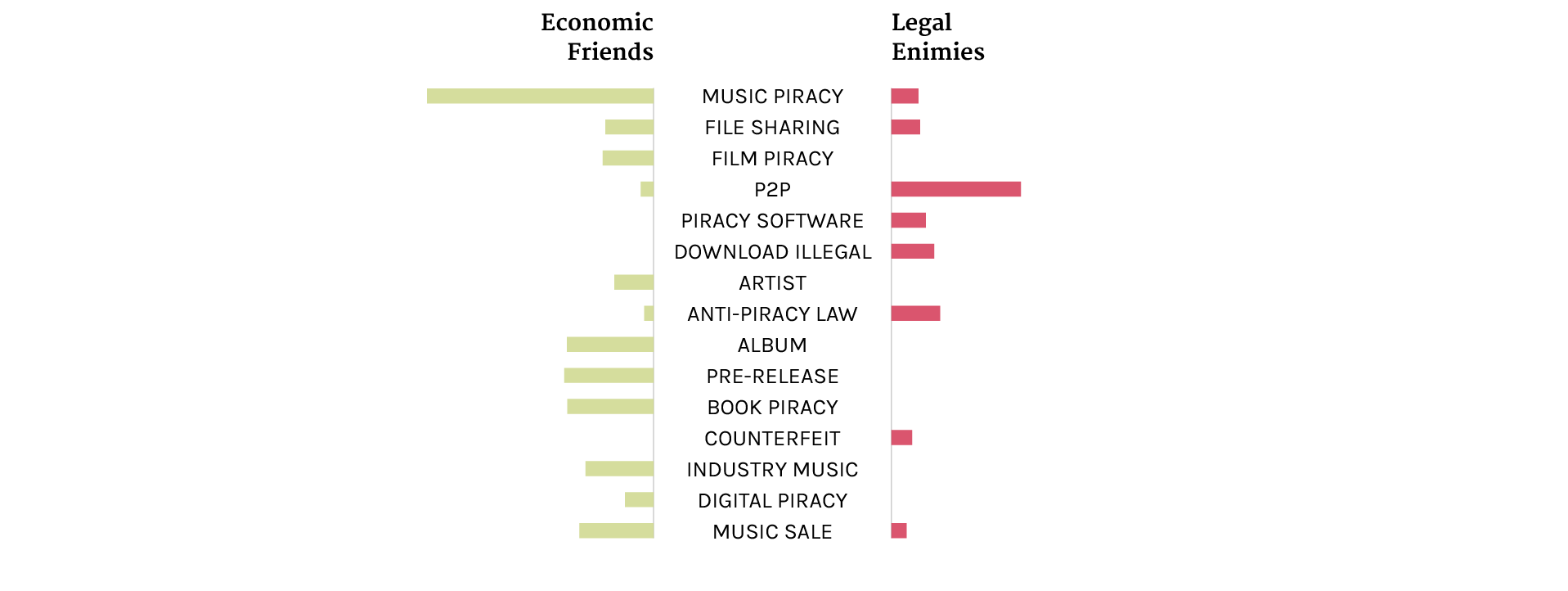
The graph shows the results of TD-IDF analysis made on the texts taken from the first 200 web pages from Google. The queries used to search are “file sharing”+ effects, “file sharing”+ consequences, piracy effects and piracy consequences. TF-IDF is a numeric statistic that is intended to reflect how important a word is to a collection of corpus. The value increases proportionally to the number of times a word appears in the text, but is offset by frequency, which helps to adjust the fact that some words appear more frequently in general.