Introduction
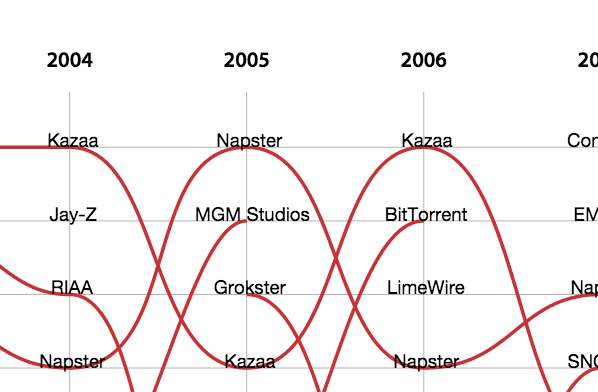
The graph shows a list with the 10 most discussed trends per year, from 2002 to 2014. These trends refer to th New York Times and The Guardian articles, and the trends are calculated by the amount of articles in which the query "File Sharing" is occurred.