Introduction
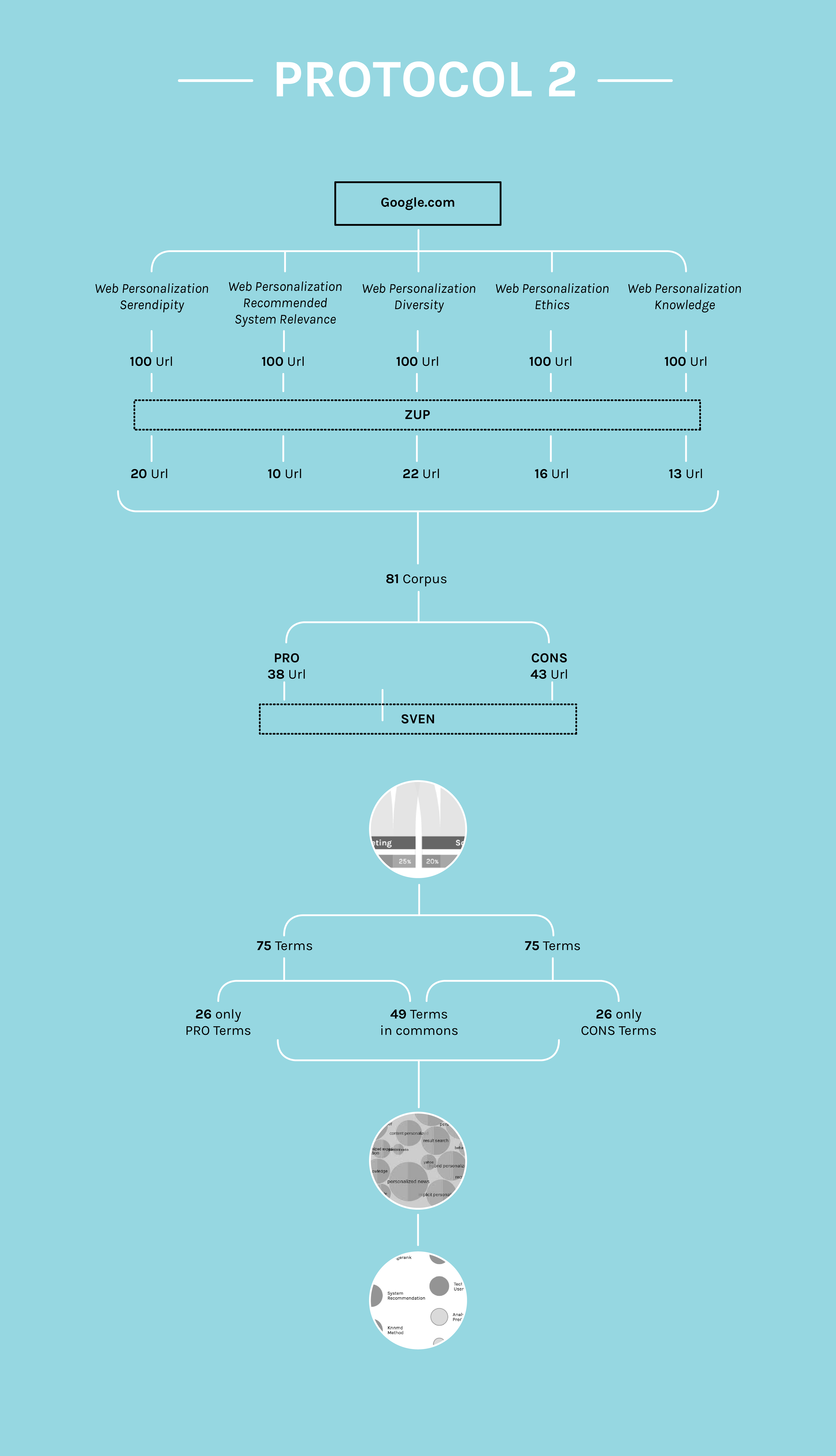
The procedure starts disconnecting from the personal Google account and opening an incognito window. Using Google.com, the setting of the research was changed to 100 results instead of 20.
Five queries were used for this protocol: “web personalization serendipity”, “web personalization system recommended relevance”, “web personalization diversity”, “ethics web personalization” and “web personalization knowledge”.
From each of the five research, the urls (URL EXTRACTOR) and the text of each url (ZUP) were extracted and insert in a spreadsheet: This was compile with different infos for each web page: Name of the article, Author, Date, Resume, Link, Position, Actors, Topic (technology, society, adv…).
The pages were divided in two corpus. In the first one belong all the Pro pages while in the second one alle the Con pages and they were text analyzed with Sven.
After, all the terms obtained with Sven were analyzed, 75 words for each of the two corpus were selected through a careful reading. 49 of them are in common for both the corpus while 26 belong only extracted for each corpus, for a total of 101 words. These terms then were divided in four categories of actors.
The outputs are three graphs:
1. Map of the term analysis.
2. The Pros and Cons by categories: technology, marketing, privacy and society.
3. Actors identified in the term analysis.