Books Analysis
Starting from the queries:
- Internet Addiction
- Digital Addiction
- Social Media Addiction (abandoned throughout the analysis)
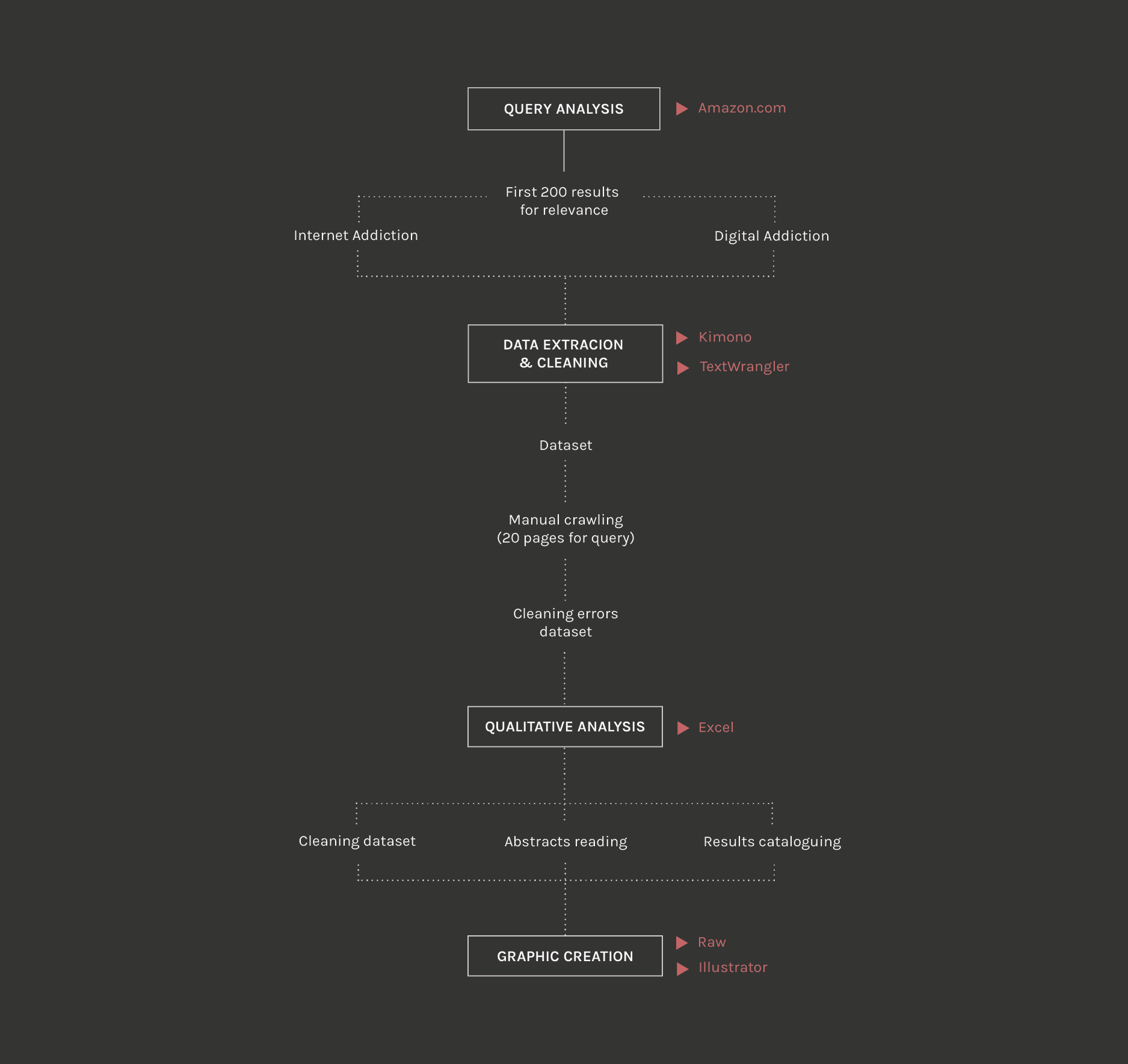
1. Each query has been typed into Amazon.com (using Google Chrome)
selecting the voice “books”. The first 200 results have been selected (approximately 20 pages each)
in order of relevance for each query
2. Once opened the first results page for each query,
the following voices have been created on Kimono:
- Title
- Author
- Data
- Reviews
- Image
In “Data Model View”, from the page “Advanced” for each voice,
“Including href” has been taken off; selecting “Crawl Setup” has been used “Manual Crawl”
and inserted the URL for the 20 following pages; once ended the Crawling the .cvs is dowloaded
3. The .csv is opened in TextWrangler,
reworked substituting “,” with “;” (dividers), then saved
as “unix (LF)-Unicode (UTF-8)”
4. Three tables have been created using Excel (one for each query)
keeping the following voices:
- Title
- Author
- Data
- Reviews
Data cleaned and fixed
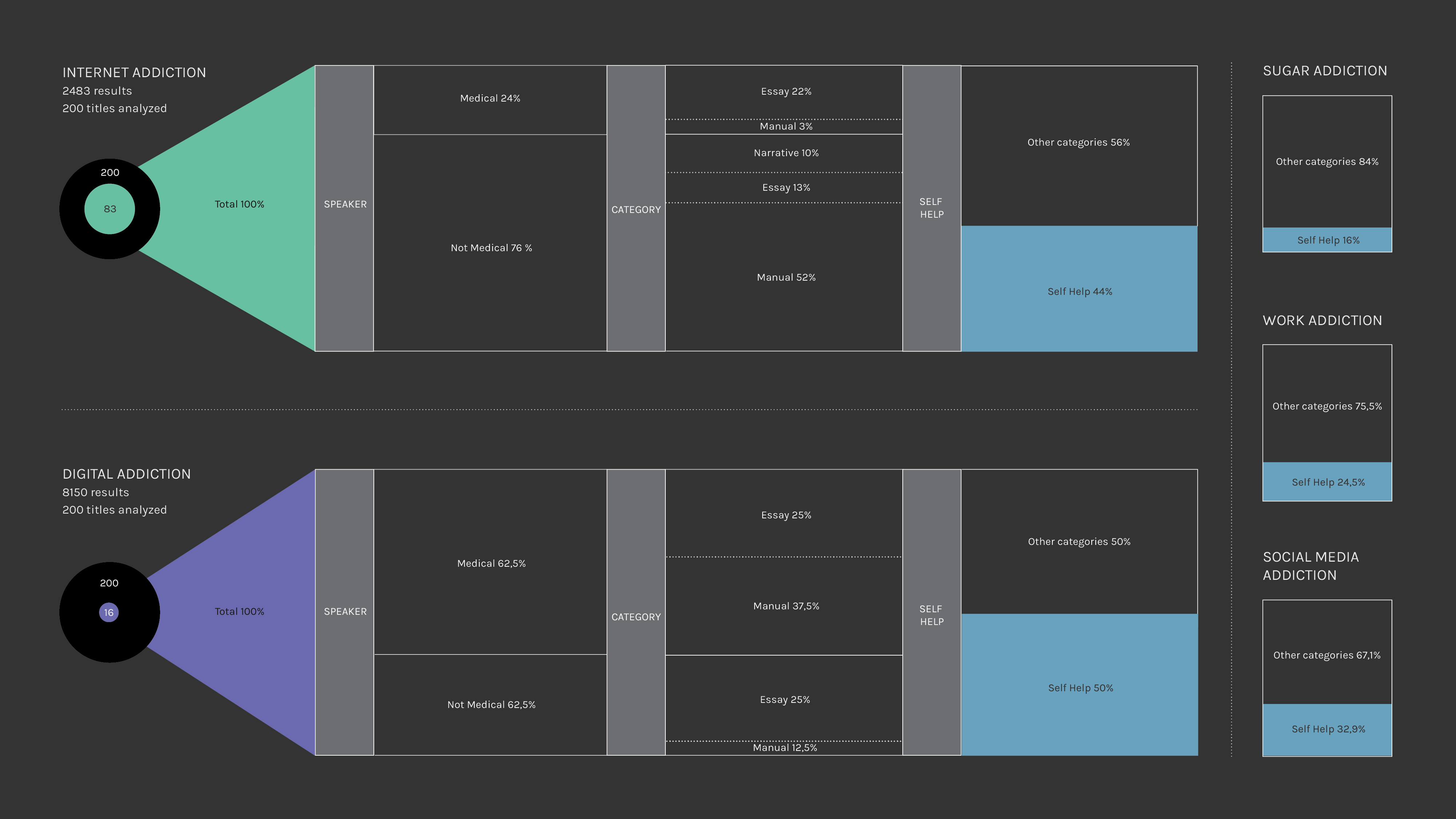
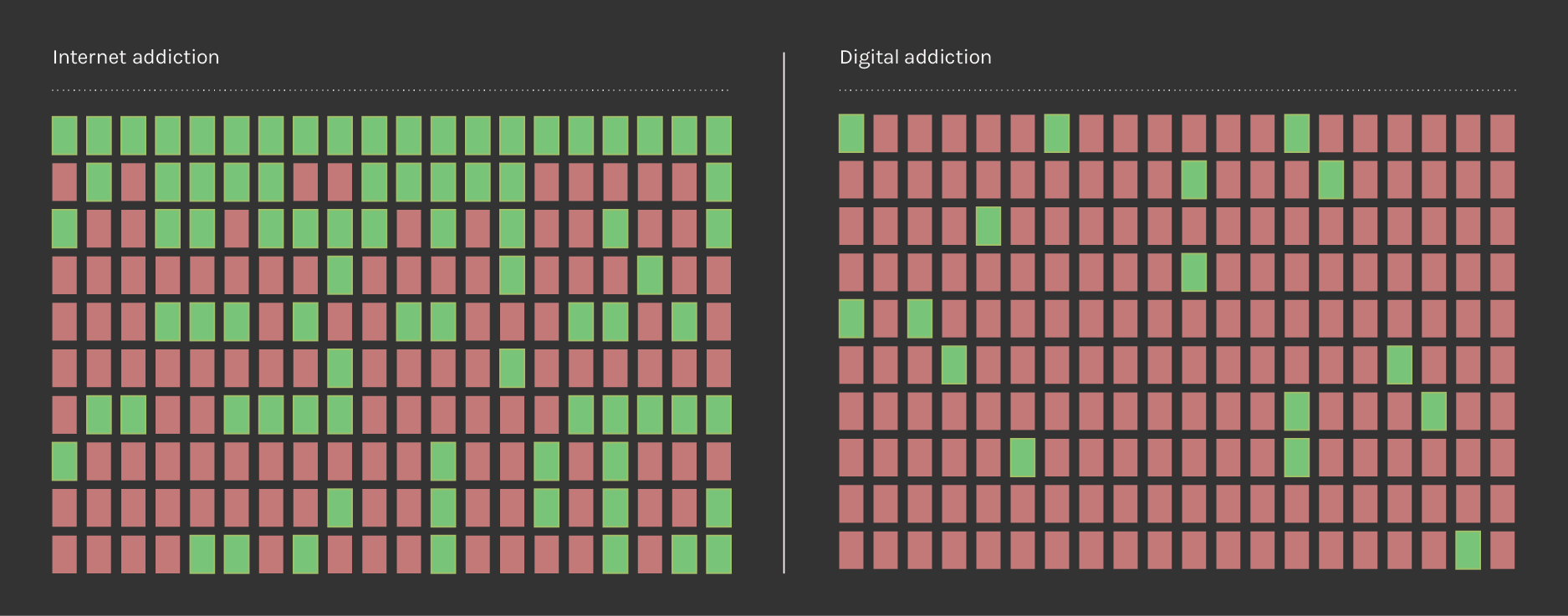
5. For each result the abstract has been read (Amazon.com) and labeled “relevant" or "non-relevant",
Three labels have been associated to each voice:
Speaker, who speaks:
- Medical (1)
- Non medical (0)
Typology, what kind of text:
- Manual (1)
- Essay (2)
- Narrative (3)
Self help, do-it-yourself remedies:
- Self Help (1)
- Others (2)
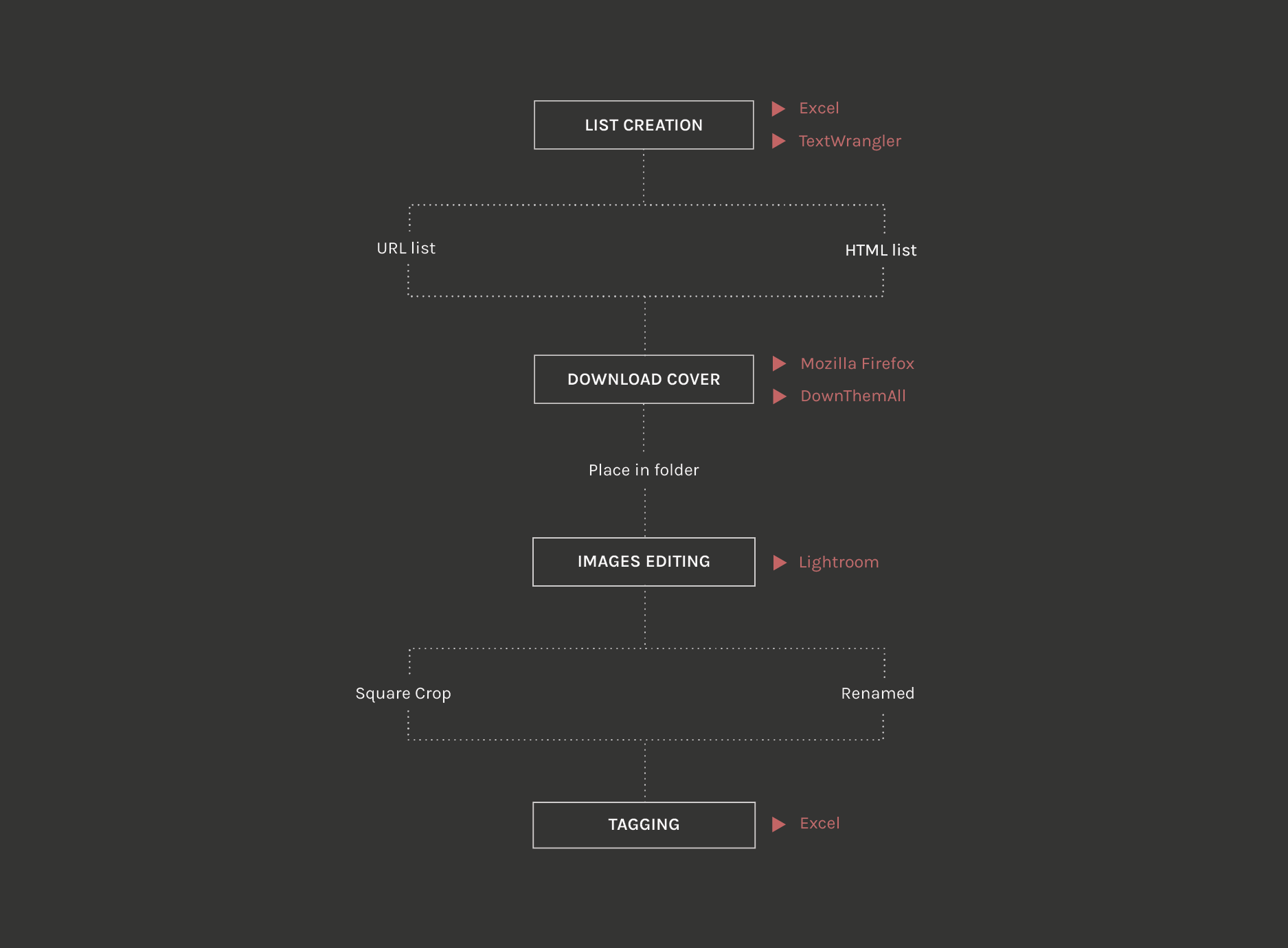
The resulting file .csv has been sorted like following:
- Query
- Title
- Author
- Reviews
- Year
- Relevant
- Speaker
- Typology
- Self Help
6. Dataset has been put in Raw generating different graphics then
arranged to compose the final one