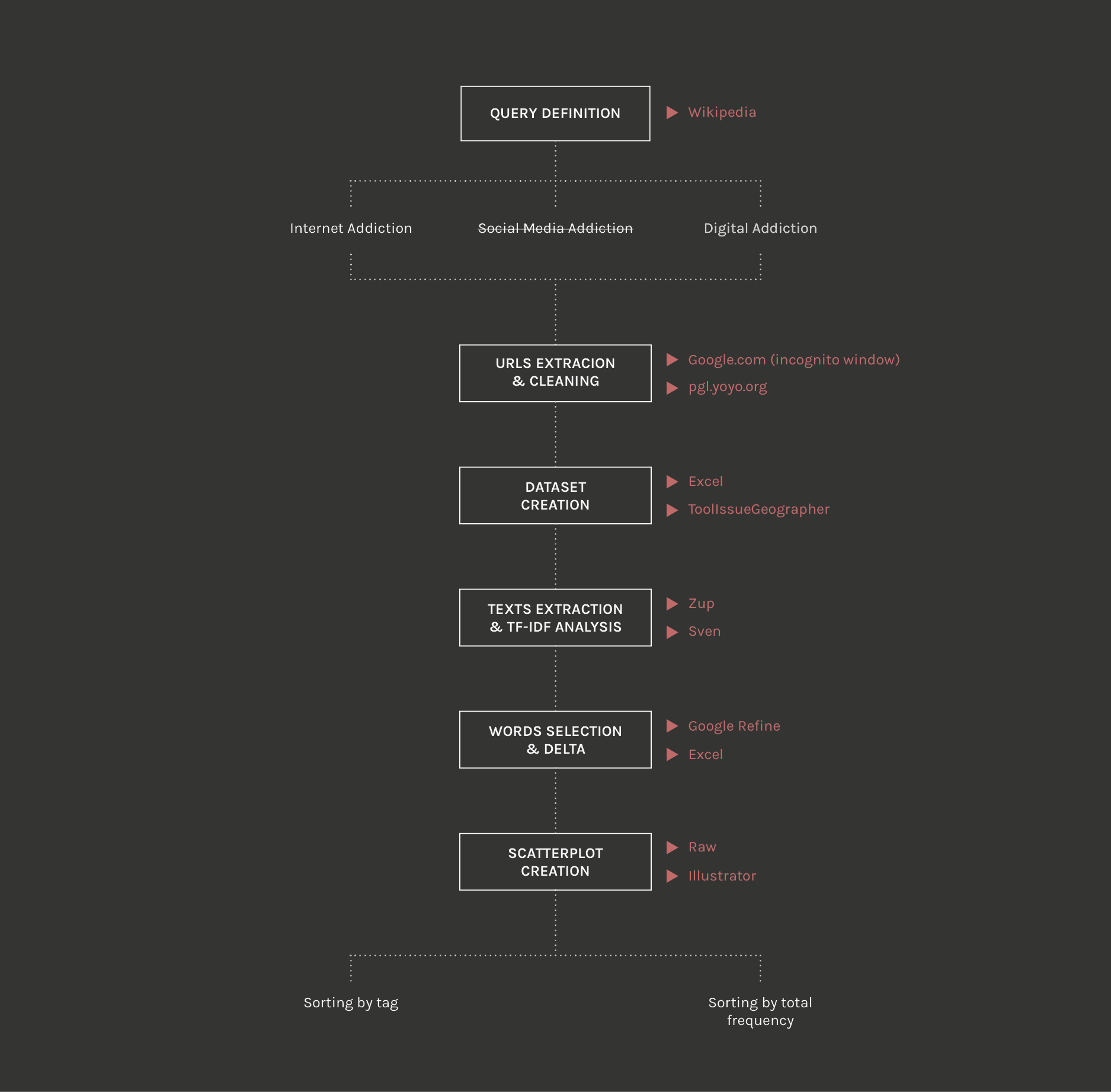
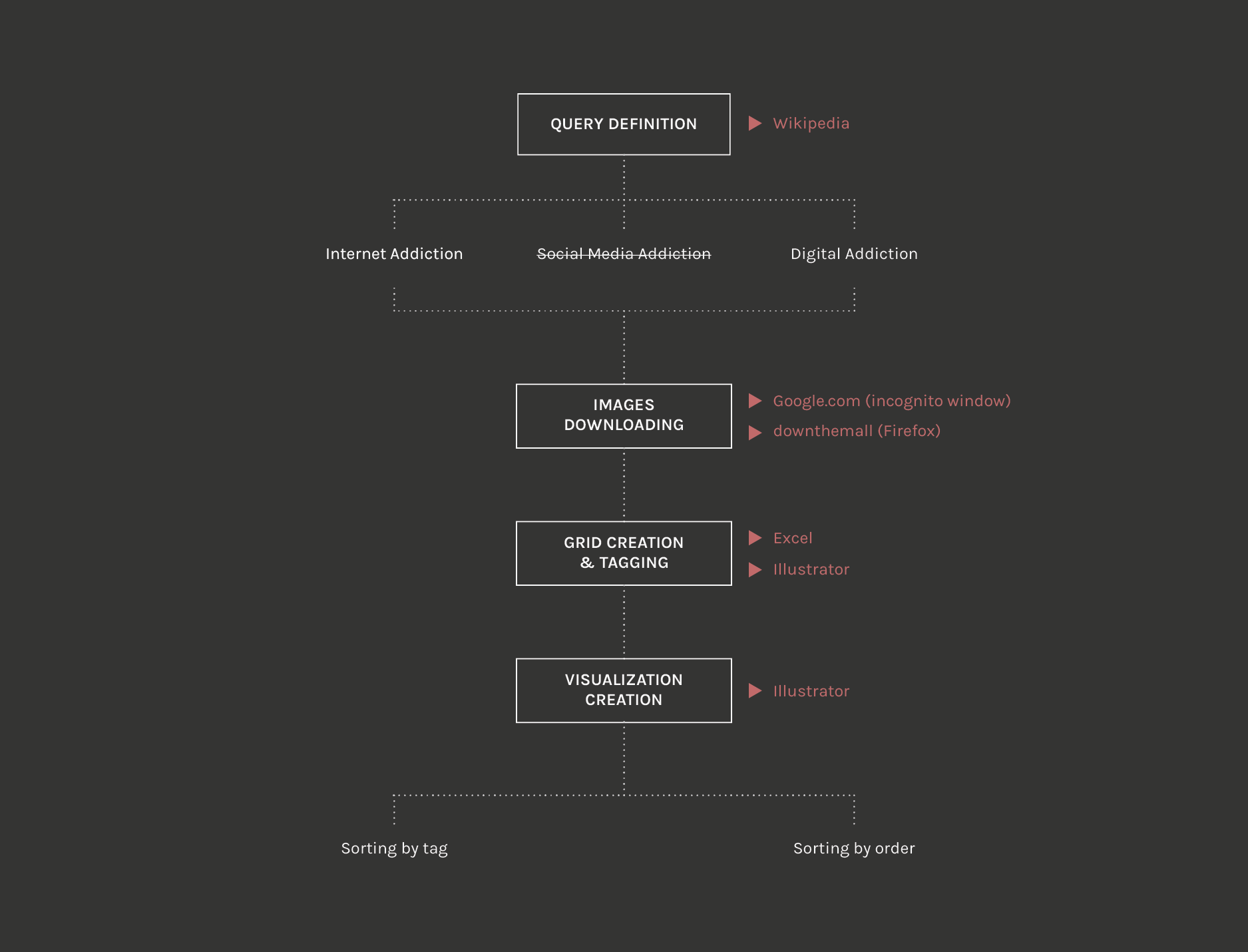
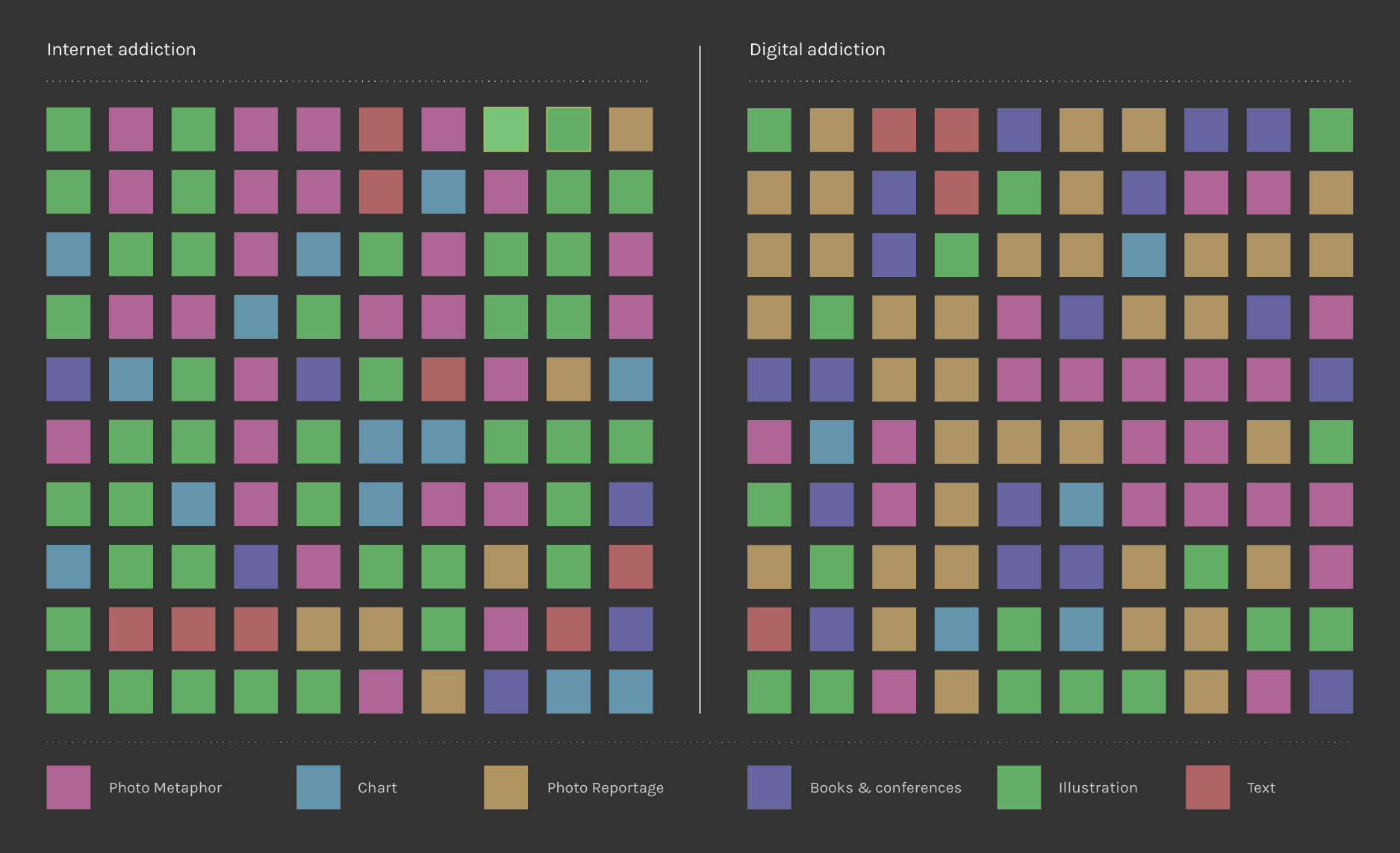
Text Analysis
Starting from the queries:
- Internet Addiction
- Digital Addiction
- Social Media Addiction (cut out proceeding with the analysis)
1. Google.com (only english pages) with incognito window navigation
2. Google.com > settings > never show instant results > results per page > 100
3. Query > left-click > view page source > cmd-a, copy and paste on Yoyo
> filter “google” > extract links
4. Excel > double links cleaned (filters > advanced > unique records only)
> excel file cleaned validating each link by reading and tagging its nature in:
- Medical
- Rehab
- News
- Blog
- Education
- Technology
- Wiki
5. Added information in the Excel dataset related to:
- Author
- Latitude
- Longitude
- IP of the website
- Short summary
- Quotes
6. Zup (user: gruppo_2; password: gruppo_2) > project rename
> cmd-v
filtered excel links > start > when done, download results > zip files extracted
7. File .txt renamed with short names (01,02, n) not to make Sven crash
8. Sven (user: gruppo_2; password: gruppo_2). It is necessary to log out from ZUP
or open it with another browser otherwise there might be identification problems
> upload all the .txt related to a query and/or a specific tag
9. TF and TFIDF (much slower) analysis and .csv download
10. .csv cleaning on Excel
11. Google Refine for the Sven analysis
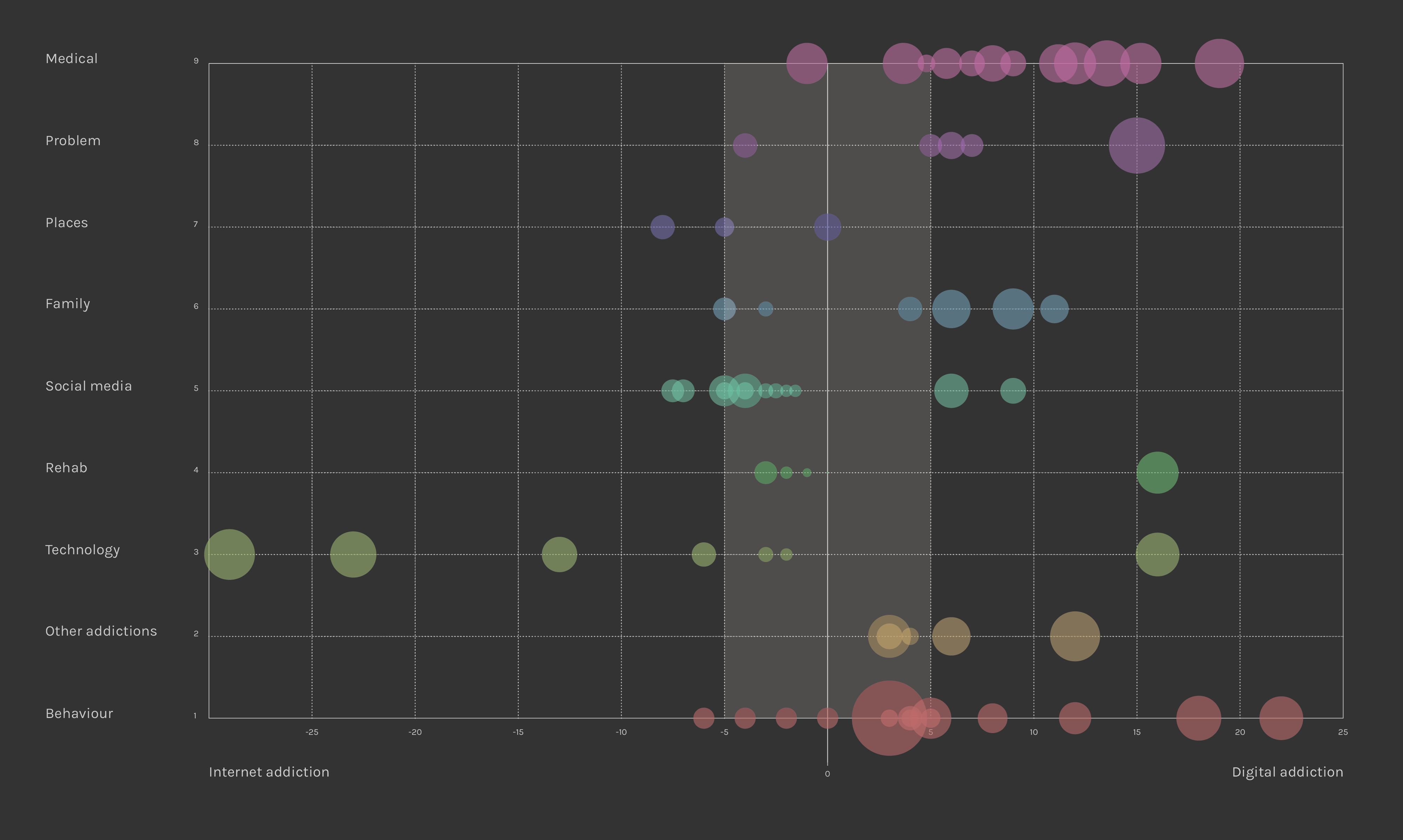
12. First 50 relevant words for each query and delta calculation between Excel frequencies
(TF Internet Addiction - TF Digital Addiction), in order to have a delta value for both queries
13. Scatterplot creation using Raw and Illustrator