Introduction
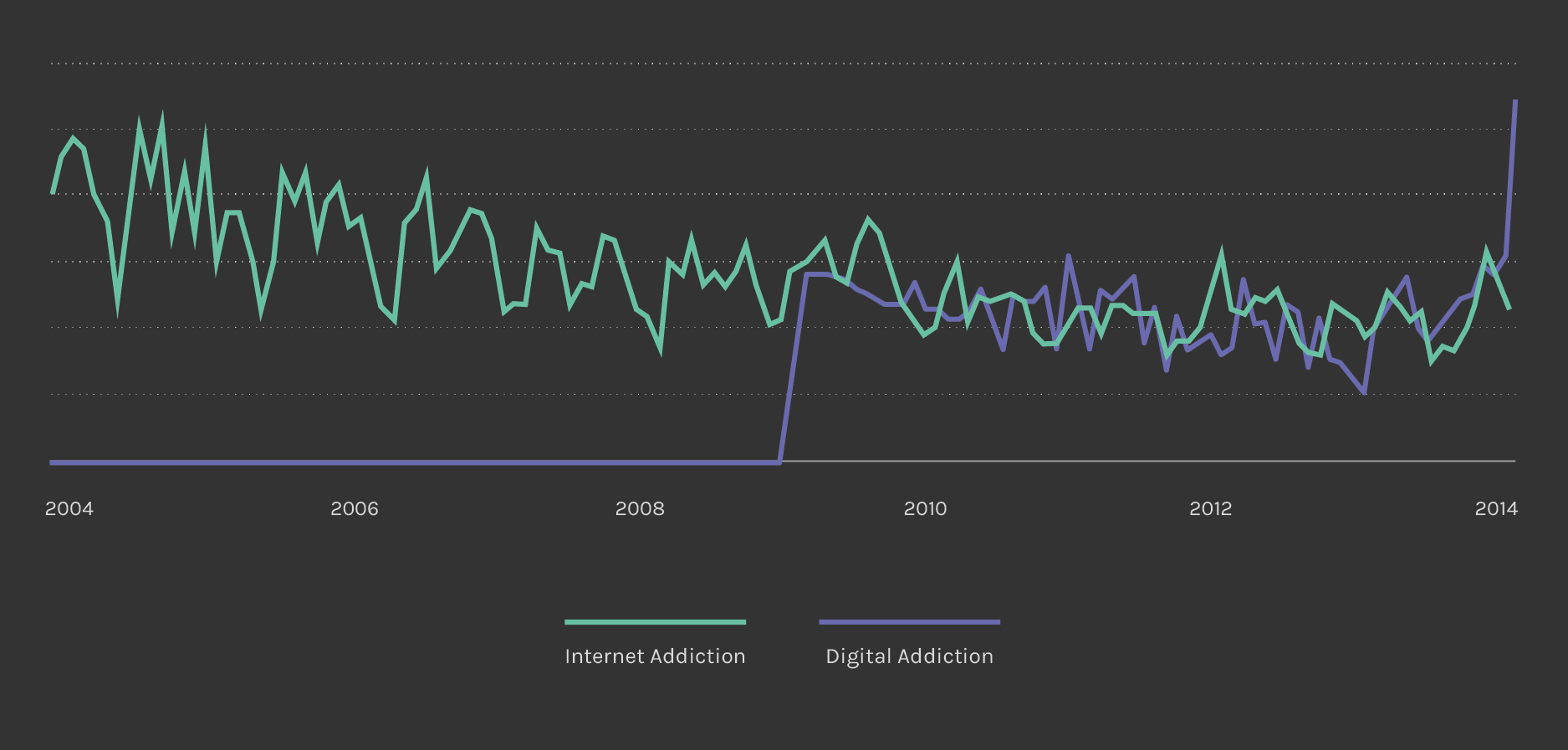
After agreeing on the queries “Internet Addiction” related to the medical world and “Digital Addiction” referred to the online community, we analysed Google results in order to have a complete mapping of the phenomenon. For each query, the first 100 results have been taken and tagged according to website, author, geographic location and year. We realised that the speakers are mainly located in the USA, while the query “Internet Addiction” is related to less recent results, as can be also seen from Google Trend (see the image below).
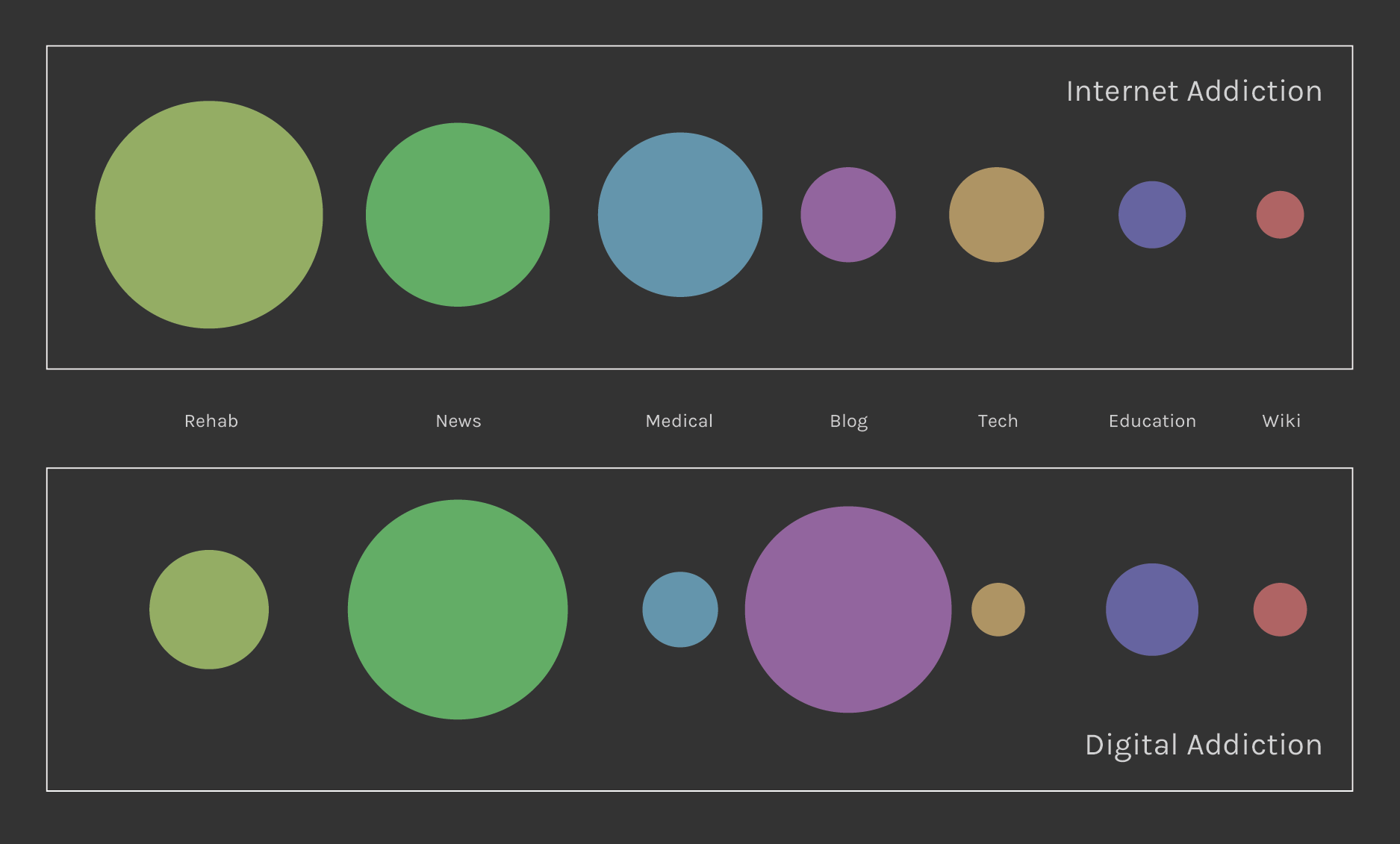
Substantial is also the difference between the quantity of websites found for each query: mostly clinical and scientific for the first one and lots of blogs and news website for the second one (see the image below).
Next step has been more qualitative: after extracting all the texts, they have been read in order to understand how the issue is discussed. We analysed their text frequency to understand the semantic importance of the most used words, which have been tagged into meaning categories. According to the results found we finally built the scatterplot.