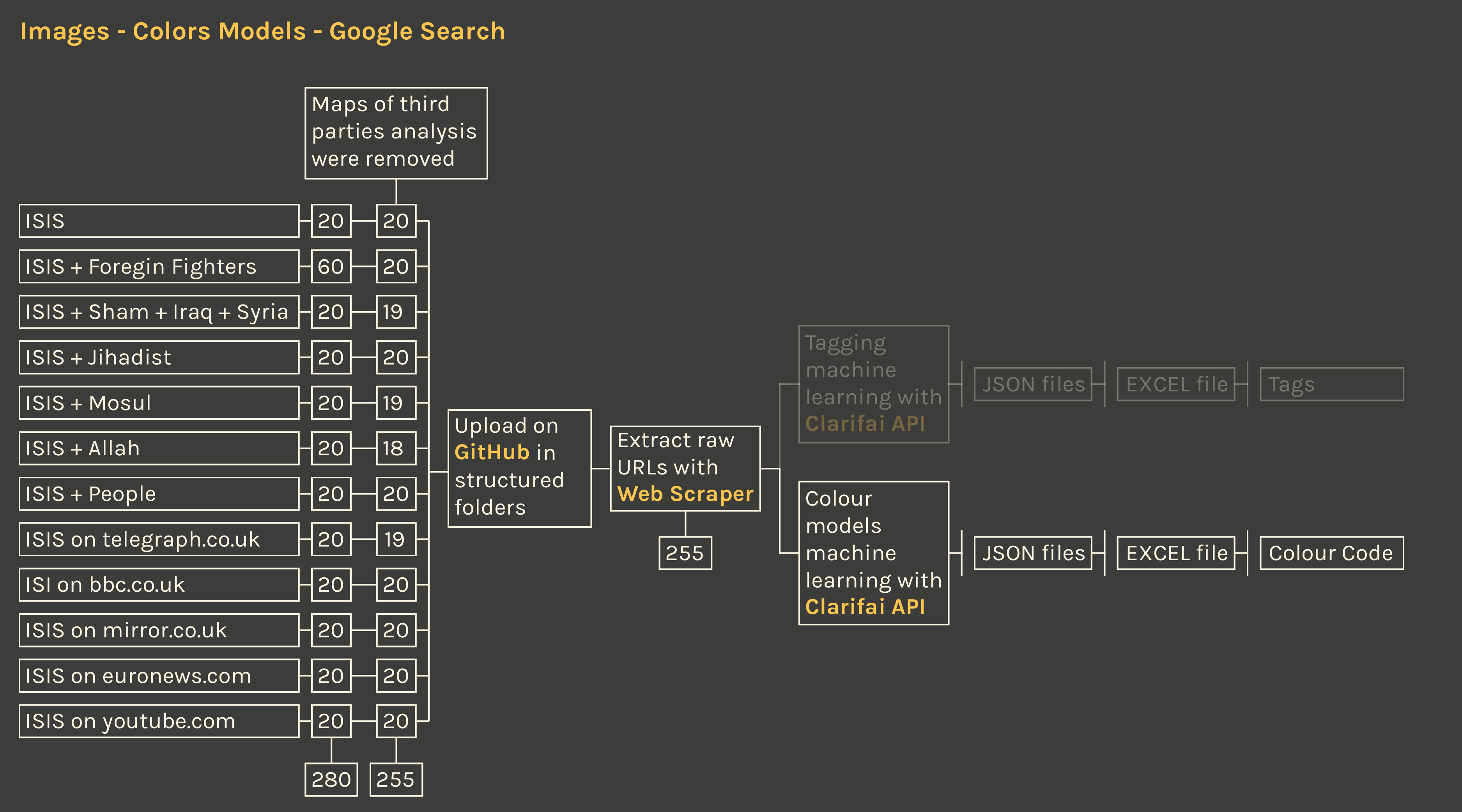
Description
The research of images on Google was done to verify how different media represent the IS in terms of visual content. The research queries were selected in order to compare different sources: (i) “ISIS” on Google images in general; (ii) “ISIS + foreign fighters” from the previous research phase; (iii) “ISIS + Allah”, “ISIS + people”, “ISIS + Sham + Iraq” are the most recurrent words in the official magazines Dabiq and Rumiyah; (iv) “ISIS + Sham + Iraq”, “ISIS + jihadist”, “ISIS + Mosul” are the words where the controversy is focused on Wikipedia based on how many times those words were changed; (v) “ISIS on telegraph.co.uk”, “ISIS on euronews.com”, “ISIS on mirror.co.uk”, “ISIS on bbc.co.uk” to filter results by european media as analyzed for news articles; (vi) “ISIS on youtube.com” to include the image given by a media largerly used for the communication of the IS on the web.
The analysis of the images with Clarifai APIs allowed to assign color models via machine learning. The comparison of the distribution of the colors per every query permits to locate the similarities and the differences between the images resulting from all the queries. The visualization shows all the color models extracted by Clarifai ordered per HEX value. It’s very apparent that all the queries share basically the same colors, moreover with the same density distribution. Hence the visual communication by the media offers a strong and homogeneous image, even though the images resulting for each query are different, yet similar. By clicking on the query name or the color models, the user can access all the corresponding images.