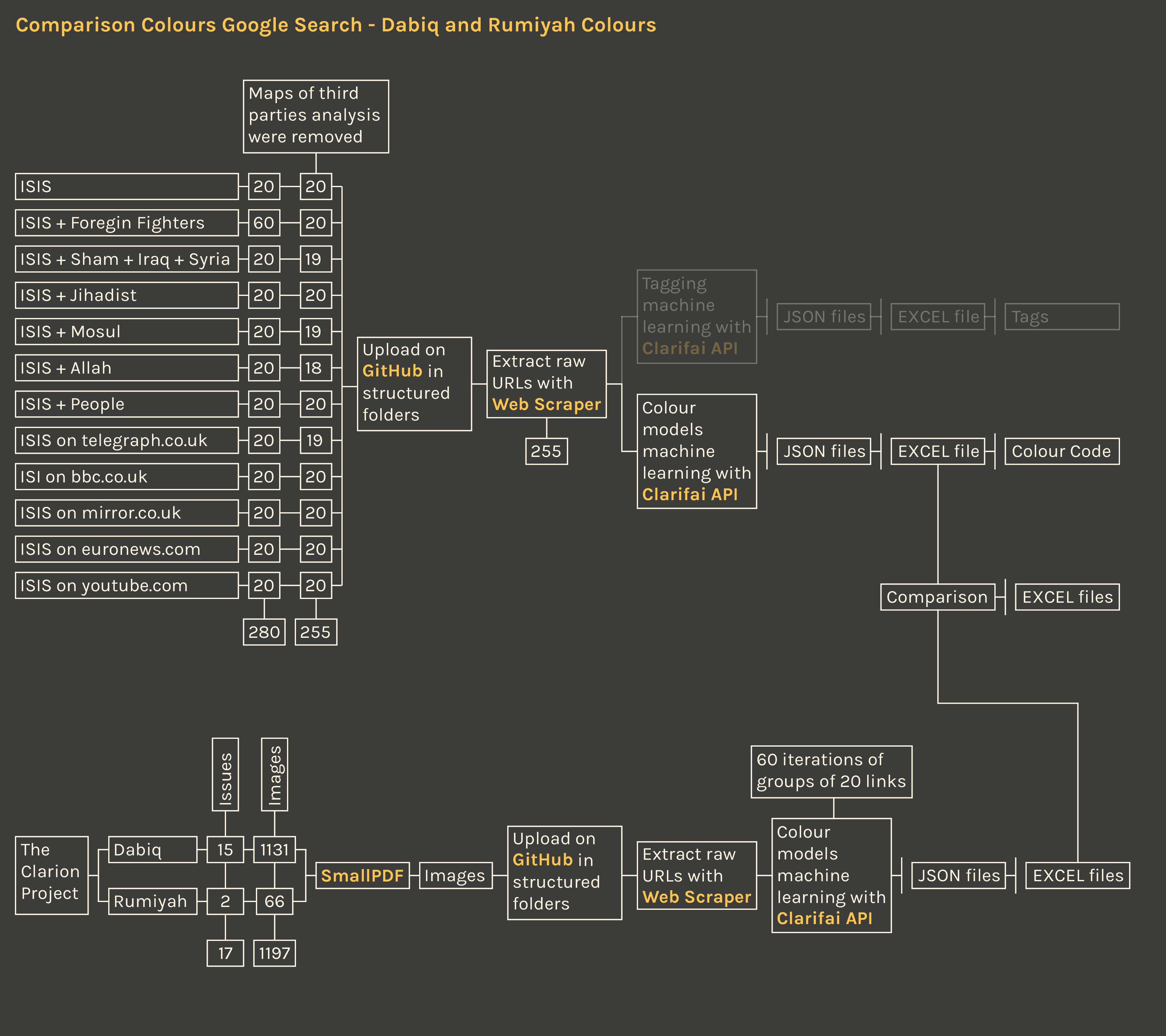
Description
Images of the official magazines by the IS and the images founded on Google Images are compared in this visualization to study where the similarities and the differences are located when considering the color models. This comparison offers an overview on the differences of standards of communication conducted by two entities that perceive the phenomenon in a diametrically opposed way. The first part shows the totality of all the color models extracted from the google images on the left and from the magazines Dabiq and Rumiyah on the right. The second part shows a synthesis of the first part displayed for direct comparison. The difference in color for the official magazine carried out by the IS and the mostly-dark colors resulting from the google images is instantly visible.