
Description
As you can see from the representation the three different newspapers have treated the subject in slightly different way, with more or less focus on different subjects inside the topic. Safety has emerged as the biggest issue related to self-driving cars in its broad range of sub-topics and aspects. Legislation and testing as well are strongly correlated to how safe the technology is and is perceived by the governments and cities. One last thing we can observe and will investigate further in a correlated question, is how the articles aren't evenly distributed across time, but the debate is denser around some key moments. The category of the articles in these key-periods will likely identify the driver events, as we can do for example with Tesla's car crash, which we easily recognized as the spark the ignited the debate across all of the three newspapers.
Protocol
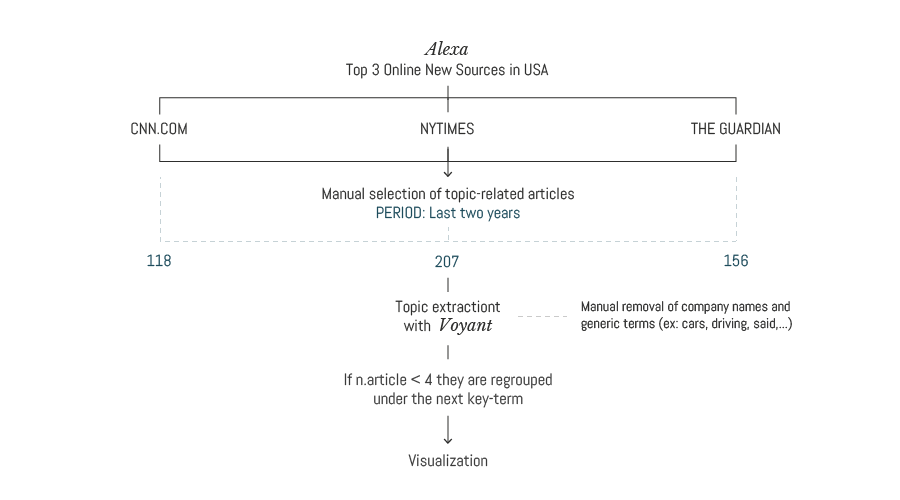
The newspapers of choice were selected through Alexa Top Sites Ranking in the News category (available at this link). Reddit, which is first on the ranking, wasn't used as we wanted to investigate the framing of traditional newspapers and Reddit As the result we were expecting was more driven towards an institutional overview of the context we decided to exclude reddit and focus on the three most read newspapers: CNN, The New York Times and The Guardian. By researching in-site the query “Self-driving car” we proceeded to manually remove all the off-topic articles. The corpus of the article was then inserted into Voyant Tools where the most used keywords were found. The category to wihch assign the article was determined by the most used keyword, company names were excluded as they often would shade the topic of the article, making it purely about a company. “Self-driving”, “car”, “autonomous” were also excluded. If the number of articles under the category were less than 4, they were re-analyzed with Voyant Tools and assigned to the next keyword.
Data
Timestamp: 01/12/2016 - 05/12/2016
Data source: NYTimes, The Guardian, CNN
Download data (4MB)
The dataset is an .xls file that contains three sheets. Each sheet contains a list of articles. They were simply divided in two columns, one with the date and the second with the relative category elaborated during the research.