Description
This last visualization highlights the important role that the major IT companies—Facebook, Google and Twitter—play in the Hate Speech & Filtering discussion, since during the analysis it has become clear that they are often accused of censorship of contents. Also Germany and US stand out from the visualization, because of their different legislative conducts and mindsets regarding Hate Speech, which often causes discussions on the theme. Finally, the figure of Nadine Strossen emerges, a writer who supports the idea that Hate Speech needs to be tackled with Free Speech and not censorship.
Considering these conclusions and the opinions emerged in the previous protocols, we can deduce that the discussion is far more complex and has much broader boundaries than what we expected, underlining the fundamental question that the Hate Speech controversy generates: who should have the responsability and the power to regulate what may or may not be said online?
Indeed, the aim of this last protocol was to produce a visual that showed which platforms deal with the Hate Speech topic, whether they speak in terms of filtering or censorship and, above all, who are the main actors in the conversation, i.e. those who are asked to take a position, those who have the power to act and bear the weight of judgment from the internet community.
The sites that express themselves on the subject have been represented with black strokes around the relative nodes. In order not to lose the controversial value of the discussion the color of the edges that originate from the platform is painted with blue if the type of speech was about filtering and orange if instead it was about censorship. The arrows lead to those who are mentioned in the speech, those spoken of. The radius of the circumferences derives from the number of times they have been mentioned, while the color depends in percentage if they have been mentioned regarding filtering or censorship. The toggles on the left help to highlight the connections between the nodes.
Protocol
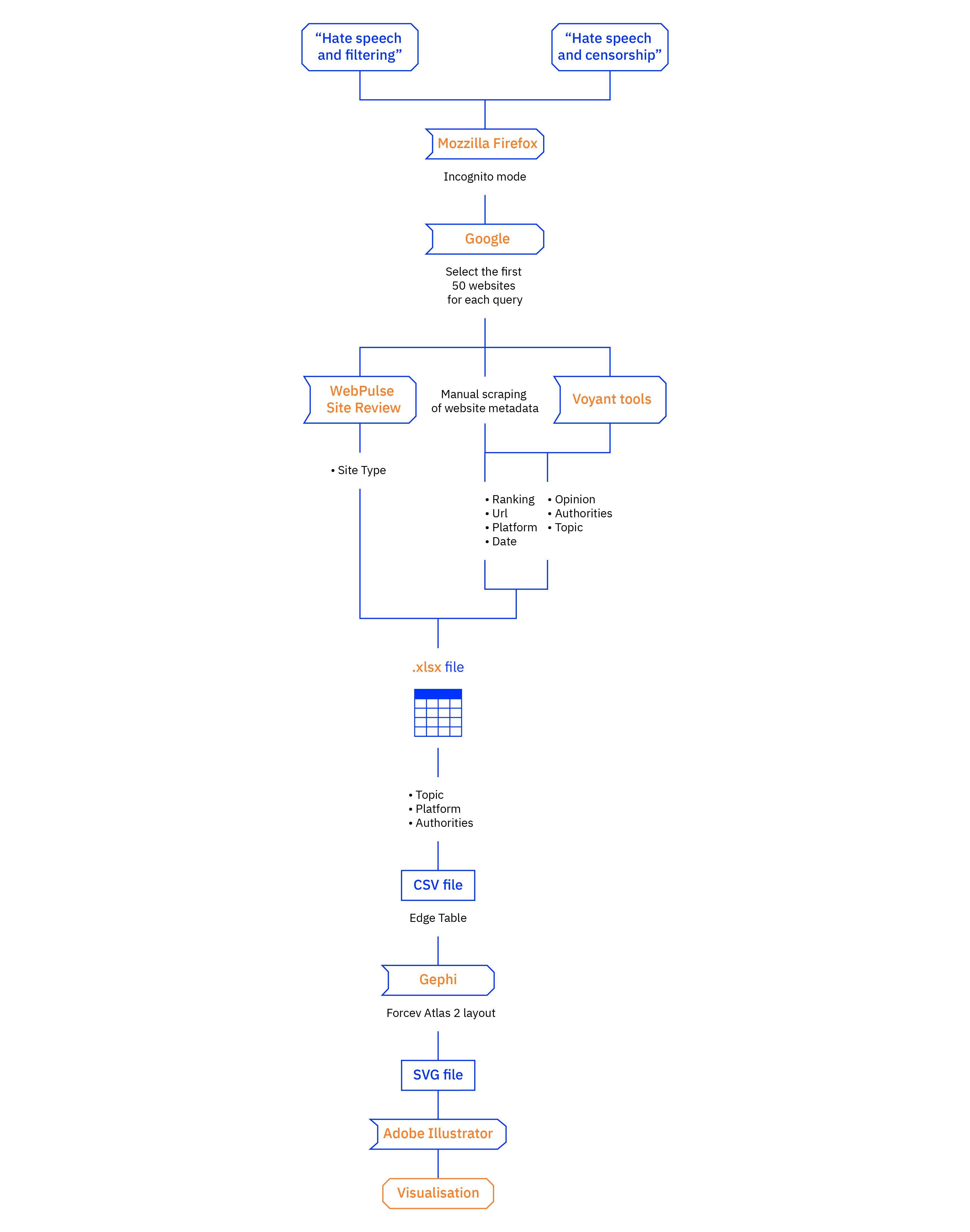
As a first step we wanted to discover what users could find on Wikipedia about filtering methods, but we discovered that there isn’t an existing Wikipedia page about this topic, so we had to search for information in a different way. We browsed Google privately in Incognito mode with Firefox and we analyzed the topic with two different queries: “Hate Speech & Filtering” and “Hate Speech & Censorship”. We decided to use both queries because there is a controversy between the two terms: “Filtering” itself has a positive connotation but there are people who believe that it is only a nice way to censor contents.
We created an Excel file where we started to collect the first 50 results for both queries, reporting also the Google rank. After this first step, we analyzed the structure of every site and we collected information about the actors which shared the content, the date in which the content was posted online and the sites typology according to WebPulse Site Review tool.
After these sites’ categorization, we analyzed what are the most frequents words used in each site according to Voyant Tools. We compared the obtained results with a manual research on the site, paying attention to the title of each article to underline what are the most important authorities in the debate and also the most shared opinions.