Description
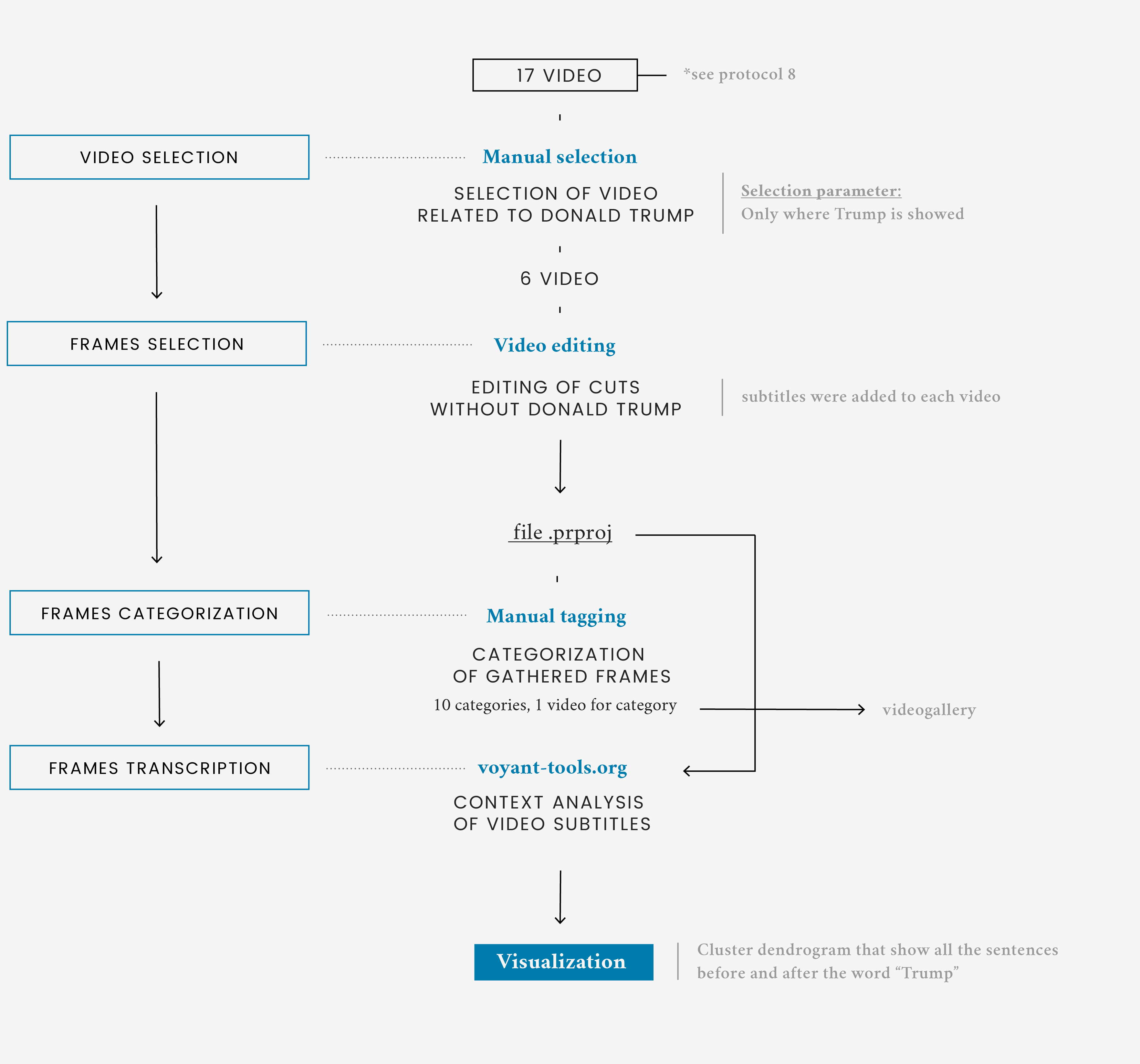
Trump’s scenes corpus selected in question 8 were only a little part of the total amount of scenes shown by the news providers. Analysing the remaining parts of the videos, the focus was on both on words and images.
The first visualization is a compilation of all the scenes not containing Trump directly speaking. Every video is a mix of scenes extracted from the starting corpus categorized by what is visually shown. Under every video there’s a bar showing the amount of time taken by the single category. The most relevant categories appear to be politics, anchors and Trump. These two last categories shows direct comments of anchormen and some scenes where Trump is shown but doesn’t speak directly.
In the second part, starting from the keyword "Trump", the visualization shows how the sentences in which he appears are articulated. Every sentence is categorized by tags related to the content.
The aim is to show a qualitative analysis of the context that revolves around Trump and climate change according to the providers by presenting both the exact sentences in the videos and a first categorization of the similar elements.